
Writing code in C is the most liberating experience that I get from programming. I don't waste hours browsing pages of documentation, or reading blogs explaining why abstruse concepts are totally necessary and cool. I don't stare at other people's code, trying to figure out what functionality (if any) is hiding behind a jumble of symbols and why they did it that way. I just think something, then code it, literally within minutes.
I like to think this attitude isn't born of ignorance or prejudice: I've written Java and JavaScript, and I use both Python and C++ as part of my job, but I still prefer C. In Star Wars terms, I see C++ as the "technological terror" with a flaw at its heart, and C as the "more civilized weapon for a more civilized age." In all likelihood, C does not represent the same things to you as it represents to me: freedom, mastery, and the (now well-thumbed) copy of K&R (2nd ed.) that my older sister gave me as a teenager.
The inventors of C correctly identified its strengths in the preface to 'The C Programming Language' (1978): it's pleasant, expressive, and versatile, but not too big, too specialized, or too restrictive. It seems to me that a lot of the complaints that people have about C can be addressed by using better coding techniques or by creating libraries to address its perceived deficiencies.
C is just as type-safe as I need it to be without forcing me to jump through pointless hoops. It supports object-oriented programming to the extent that I need it to without forcing everything to be a class or requiring me to write hundreds of lines of boilerplate code. In summary, C fits me like an old comfy jacket with patched elbows. I'm increasingly aware that this puts me in a minority: most of the world has since moved on, although new versions of the C language standard are still published (e.g. C23).
I was recently surprised to hear Guido van Rossum say that his favourite language (apart from Python) is C. Of course, Python was written in C and borrows ideas from C, but I was still surprised because hearing anything positive about C is rare nowadays. Many developers are proud to stand up and proclaim "C is a bad language", despite its crucial role in creating much of the modern world which surrounds them. The same developers then sit down and unthinkingly carry on using software written in C (git, Python, Linux, etc.) to do their job!
Having invested so much of my life into C programming, this dismissive attitude makes me feel sad and a little angry, as though someone had insulted a member of my family. Bjarne Stroustrup once said "There are only two kinds of languages: the ones people complain about and the ones nobody uses". Perhaps it follows that I shouldn't be too sensitive about people complaining about my favourite language. I'm working on improving that aspect of myself.
It's easy to criticise C's syntax; there's even a website to translate between "C gibberish" and English, which is a lot of fun. Also, let's not forget the International Obfuscated C Code Contest, which has been "celebrating [C's] syntactical opaqueness" since 1984.
I find that the most valid (but comparatively rare) criticism
of C's syntax is its verbosity. When combined with the fact
that there's no type inference, and no implicit
this or self pointer in method
definitions, the result is typically a lot of repetitive and
longwinded declarations.
Here's a declaration of a constant pointer to a constant
unsigned integer which must be at least 64 bits wide (i.e.
x must always point to y, and
y cannot be changed by dereferencing
x):
unsigned long long int const *const x = &y;
In reality, this would probably be written using a type alias:
uint64_t const *const x = &y;
I once joked that we are approaching a "const singularity": a
hypothetical moment in time when every symbol in every C
program is the type-qualifier const. Objects are
mutable by default, yet most objects can be initialized at
the point of declaration and should not be modified
thereafter. This is especially true if a program is written
in the modern style whereby declarations can be mixed with
other statements.
Declarations do not read straightforwardly from left-to-right
(or right-to-left) because * (pointer-to) has
right-associativity (to its operand), whereas [
and ( have left-associativity. I admit that I
take perverse pleasure in seeing novice programmers confront
the horrifying reality that C declarations are parsed
inside-out and back-to-front!
Kernighan & Ritchie explained the reasoning behind this syntax in The C Programming Language' (1988):
The declaration of the pointer ip,
int *ip;
is intended as a mnemonic; it says that the expression *ip is an int. The syntax of the declaration for a variable mimics the syntax of expressions in which the variable might appear.
The grammar used in appendix A of K&R (2nd ed.) specifies
that a declarator is an expression of the form
pointeropt direct-declarator, where
pointeropt is zero or more instances of
* type-qualifier-listopt, and the
direct-declarator is either:
( declarator
), or
[ constant-expressionopt
], or
( parameter-type-list ).
The latter two choices represent an array and a function, respectively.
The upshot is that a declarator can specify multiple levels of indirection without recourse to brackets, which are required only for a pointer to an array or function (when nesting another declarator within the first).
Here's a declaration of a pointer (named roundf)
to a function which takes a floating point number as its
argument and returns an integer which is at least 16 bits
wide:
int (*roundf)(float);
When parsing the above declaration,
pointeropt cannot match anything until after
the recursive rule for direct-declarator has
decomposed "(*roundf)(float)" into a
parameter-type-list, "float", and another
declarator, "*roundf":
|
|||
|
|
||
|
|
||
|
|||
|
|||
|
|
||
|
|
||
|
|
|
|
|
|
||
|
|||
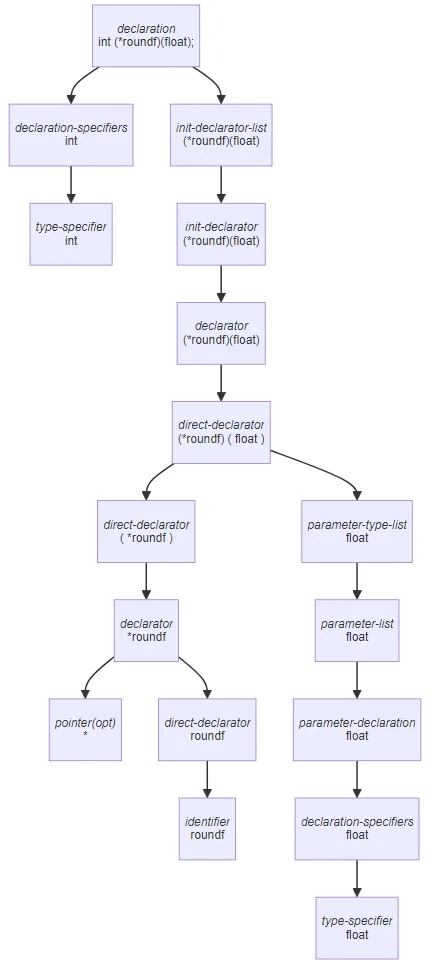
In other words, the type of the top-level declarator
(*roundf)(float) is int and the
type of the nested declarator *roundf is
int ()(float).
Without brackets to override the greediness of
*, the following statement instead declares a function
(named roundf) which returns a pointer to an
integer:
int *roundf(float);
This is because the pointeropt part of the declarator rule matches straightaway, unlike in the previous example:
|
|||
|
|
||
|
|
||
|
|||
|
|
||
|
|
||
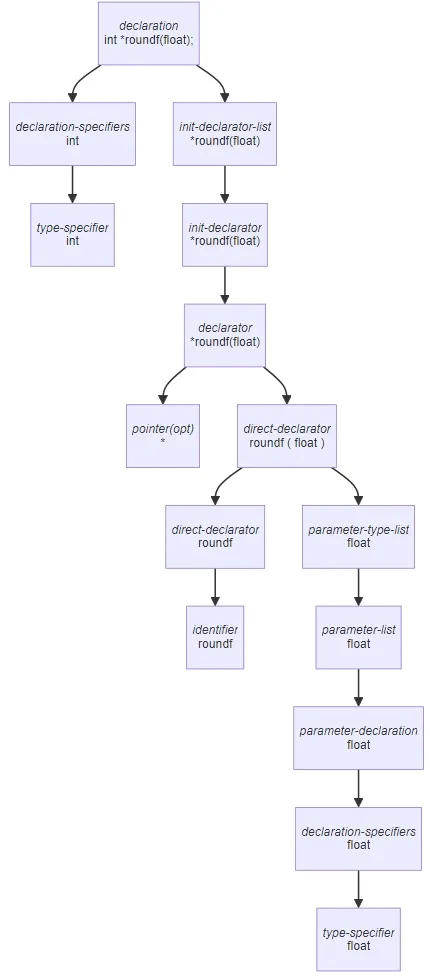
In other words, the type of declarator
*roundf(float) is int.
Here's a declaration of a function (named
get_roundf) which takes a single Boolean argument and
returns a pointer to a function that returns an integer:
int (*get_roundf(_Bool to_nearest))(float);
The type of the top-level declarator
(*get_roundf(_Bool to_nearest))(float) is
int and the type of the nested declarator
*get_roundf(_Bool to_nearest) is int
()(float).
In practice, most programmers use typedef to
define aliases for types, and then compose more complex
declarations from those aliases. The declaration above could
be simplified thus:
typedef int roundf_t(float); roundf_t *get_roundf(_Bool to_nearest);
You might be wondering what the above declarations would look like if the pointer-to operator were instead left-associative:
int roundf*(float); // pointer to a function returning int int roundf(float)*; // function returning a pointer to int int get_roundf(_Bool to_nearest)*(float); // function returning a pointer to a function returning int
Stroustrup proposed a similar postfix declaration syntax in
"The Design and Evolution of C++" (1994), but using
-> instead of *:
int f(char)->[10]->(double)->;
This mooted change
doesn't lend weight to his habit of writing
int*
instead of
int *:
pointeropt can never be part of the type-specifier because it can be used to indicate indirection at various different levels (or none) within different declarations in an init-declarator-list.
For example:
int (*roundf)(float), // pointer to a function returning int
*roundf(float), // function returning a pointer to int
(*get_roundf(_Bool to_nearest))(float); // function returning a pointer to a function returning int
Short of moving the entire type specification (everything except the identifier) to the lefthand side, Stroustrup's style is incoherent.
At best, misuse of whitespace is wishful thinking; at worst, it can be very misleading. The following code looks as though it declares three pointers to integers. In fact, it declares one pointer (a) and two integers (b and c):
int* a, b, c;
It's easy to criticise C's lack of language-level support for object-oriented programming (classes), generic programming (templates), and functional programming (lambdas, closures, lazy evaluation). However, that pre-supposes that languages should explicitly support every programming paradigm that has arisen or might arise.
I've read that there are four pillars of object-oriented programming:
These aren't actually very original. It's not as if encapsulation and abstraction didn't exist before Smalltalk, Java and C++. I guess all ideologies appropriate (or incorporate, to be less pejorative) common goods for themselves. That's fine but it does give rise to logical fallacies such as "we could not have morals if God did not exist", "we could not have sharing without Soviets of people's deputies" or "we can't hide implementation details without classes".
The core idea of OOP is the bundling of data and code into
objects. C's type system ensures that functions can only
operate on the user-defined types (struct or
union) specified by their parameter list. The
programmer may add an extra layer of organization by putting
the definitions of functions which operate on a given type in
the same place as the definition of that type. I'm sure that
programmers were doing so long before the invention of
languages which advertise OOP as a feature.
C certainly does support abstraction (functions, input/output
streams) and encapsulation (incomplete struct or
union types). Incomplete types can be used in
any context where the size of an object is not needed and its
members are not accessed directly:
struct encapsulated; struct encapsulated *get_encapsulated(void); struct encapsulated *e = get_encapsulated(); // Okay e->x = 0; // error: incomplete definition of type 'struct encapsulated'
Even without this safety net, it's usually obvious when you
are breaking encapsulation, e.g. by accessing a
struct member directly in a function that doesn't
implement a method for that data type.
In C++, a programmer might instead make use of a type whose members are private (which is the default for a class but not for a struct):
class encapsulated {
int x;
};
encapsulated *get_encapsulated(void);
encapsulated *e = get_encapsulated(); // Okay
e->x = 0; // error: 'x' is a private member of 'encapsulated'
Support for inheritance is where C is weakest (some might say non-existent). In any case, inheritance seems to have been going out of fashion in favour of composition ('has a' rather than 'is a' relationships).
It's possible to implement something like inheritance in C by
nesting a struct containing member variables for
a superclass inside a struct representing a
subclass, although objects of the subclass (obviously) cannot
be used interchangeably with objects of the superclass:
struct superclass {
int (*getc)(struct superclass *);
size_t count;
};
struct subclass {
struct superclass super;
FILE *f;
};
Either both types must be complete so that relevant
(superclass) member of the subclass's struct can
be accessed directly, or the programmer must provide a
subclass method (i.e. function) to return the address of the
embedded superclass object:
struct superclass *subclass_get_superclass(struct subclass *s)
{
return &s->super;
}
In C++, the equivalent code would use inheritance, therefore upcasting would be implicit (s instead of &s->super):
class superclass {
public:
virtual int getc();
protected:
size_t count;
};
class subclass : superclass {
public:
int getc();
private:
FILE *f;
};
In OOP terms, polymorphism usually implies virtual methods.
Virtual methods allow classes to override their superclass's
implementation of some functionality. This can be implemented
in C using function pointers (such as the getc
member of the struct superclass definition
above).
I typically hide the dereferencing of such pointers behind ordinary functions which are passed the address of a superclass instance, to ensure that the explicit 'this' pointer passed as the first parameter to each virtual method is the correct object's address, and to avoid requiring callers to have the complete type of the struct containing the function pointers:
int superclass_getc(struct superclass *s)
{
return s->getc(s);
}
This is almost identical to the syntax for calling a method in C++:
int superclass_getc(superclass *s)
{
return s->getc();
}
However, many C users find such boilerplate code too fussy relative to the encapsulation and safety benefits it provides.
The main drawback of implementing polymorphism using function pointers is a certain lack of type-safety. Downcasting is inherently unsafe, but it is necessary in most virtual method implementations written in C.
A virtual method written in C cannot access member variables using a typed pointer to an instance of the appropriate subclass; instead, it receives the address of the superclass object, and/or a void * pointer to subclass-specific data (depending on the mechanism).
The address of the subclass object is typically calculated
from the address of the superclass object using a de facto
standard macro, container_of(), which hides the required casts:
static int subclass_getc(struct superclass *s)
{
struct subclass *sub = container_of(s, struct subclass, super);
int c = fgetc(sub->f);
if (c != EOF) {
s->count++;
}
return c;
}
A good implementation of container_of() will also check that the types of s and the super member of struct subclass match. Alternatively, if the virtual method receives a void * pointer then C will seamlessly convert it into a pointer to the appropriate type upon assignment to a local variable.
In practice, the necessity of downcasting within virtual methods written in C doesn't bother me because I normally implement one subclass per source file. Only one subclass's struct is defined in each translation unit, therefore there is little risk of confusion between them.
In C++, the equivalent method definition could implicitly access member variables (including inherited variables like count, if declared as public or protected in the superclass):
int subclass::getc()
{
int c = fgetc(f);
if (c != EOF) {
count++;
}
return c;
}
This seems like a great time-saver until you realise that it's impossible to distinguish count and f from local variables, global variables, or parameters of the same name. Don't panic! You just need a naming convention; the prefix m_ is a common one. Now, you're writing expressions like m_count++. Not so different from m->count++, is it?

C has always had some support for
generic programming via its preprocessor, which can be
used to #define named tokens and function-like
macros, concatenate macro arguments to create new tokens, and
#include chunks of code that has been
genericized using macros and/or typedef.
For example, here is a macro definition of a parametrically polymorphic function that is later instantiated for type int:
#define GENERIC_SQUARE(T) T square_ ## T(T num) \
{ \
return num * num; \
}
GENERIC_SQUARE(int)
int main(void)
{
return square_int(2);
}
In C++, the equivalent code would use a template (here, explicitly instantiated):
templateT square(T num) { return num * num; } template int square (int); int main() { return square<int>(2); }
In C++, templates can alternatively be implicitly instantiated:
templateT square(T num) { return num * num; } int main() { return square(2); }
If many related definitions need to be parameterized in a C program, it may be preferable to put them in a separate file:
// generic-powers.c
#ifndef T
#error Missing parameter
#endif
#ifndef CONCAT
#define CONCAT2(a, b) a ## b
#define CONCAT(a, b) CONCAT2(a, b)
#endif
T CONCAT(square_, T)(T num)
{
return num * num;
}
T CONCAT(cube_, T)(T num)
{
return num * num * num;
}
#undef T
To instantiate such definitions, parameter values must be defined before including the file:
#define T int
#include "generic-powers.c"
int main(void)
{
return square_int(2) + cube_int(3);
}
C11 added support for ad hoc polymorphism (automatic selection of a function according to its argument types) via the _Generic() keyword, which is normally wrapped in a macro definition:
int squarei(int num) {
return num * num;
}
float squaref(float num) {
return num * num;
}
double squared(double num) {
return num * num;
}
#define square(num) _Generic(num, \
int: squarei, \
float: squaref, \
double: squared)(num)
In C++, the equivalent code could use function overloading:
int square(int num) {
return num * num;
}
float square(float num) {
return num * num;
}
double square(double num) {
return num * num;
}
But what if we need the address of 'square'?
A C++ compiler would try to guess which function's address is desired from contextual type information; a C compiler would simply report that 'square' does not exist (because the function-like macro of that name does not get expanded without brackets). Compilation of C is vastly simpler than compilation of C++, but the facilities provided by C++ are not vastly superior.
Instead of attempting generic programming, I tend to
implement algorithms using a type likely to be able to
represent any value (e.g. long instead of
int), store user data addresses in void *
pointers (gasp!), wrap a generic struct (e.g. a
linked list node) in a type-specific one, or simply copy and
modify an existing implementation of the same algorithm
(boo!). Code duplication isn't always the worst
solution to a problem, if the resultant code is readable,
safe, and correct.
Lambdas are anonymous nested function definitions which can
access objects declared within the scope of their parent.
This makes the common pattern of a 'callback function'
type-safe and convenient. In C, such functions instead have
to be named, declared with file scope, and can only access
objects within the scope of their parent via a void
* pointer or container_of(). Multiple
objects to be accessed by a callback must be bundled together
in a struct.
Recently, I prefer iterators instead of callback functions.
These side-step the problem of accessing objects in the
parent function's scope by never leaving it: the
for statement (or equivalent) controlling iteration is
part of the parent function, and the loop body contains the
code that would otherwise have been in a callback function.
Looking at C++ code provokes uneasy feelings of strangeness mixed with familiarity, like the uncanny valley. Maybe it is like seeing the face of an old friend who has been disfigured — luckily I've never had that experience. Sometimes I think the fact that C is too similar to C++ fans the flames of ill-feeling between supporters of rival camps, like a schism between different sects of the same religion. Certainly there are no compatibility wars between C and Java programmers.
I highly recommend Stroustrup's book, "The Design and Evolution of C++" (1994). It provides valuable insights into his thinking and it confirmed things I had long suspected. Much of the book is about things that he wanted to change, but couldn't, and his feelings about C and its users.
I find it striking that when Stroustrup first introduces a
class definition in his book, he makes no effort
to explain why this representation is superior to the
equivalent struct and function declarations.
C with Classes example (from Stroustrup, 1994):
class stack {
char s[SIZE]; /* array of characters */
char* min; /* pointer to bottom of stack */
char* top; /* pointer to top of stack */
char* max; /* pointer to top of allocated space */
void new(); /* initialize function (constructor) */
public:
void push(char);
char pop();
};
Equivalent code in C (using Linux kernel coding style):
struct stack {
char s[SIZE]; /* array of characters */
char *min; /* pointer to bottom of stack */
char *top; /* pointer to top of stack */
char *max; /* pointer to top of allocated space */
};
void stack_new(struct stack *); /* initialize function (constructor) */
void stack_push(struct stack *, char);
char stack_pop(struct stack *);
Or, more concisely (but still using standard C):
typedef struct {
char s[SIZE]; /* array of characters */
char *min; /* pointer to bottom of stack */
char *top; /* pointer to top of stack */
char *max; /* pointer to top of allocated space */
} stack;
void stack_new(stack *); /* initialize function (constructor) */
void stack_push(stack *, char);
char stack_pop(stack *);
Certainly, the class definition is more
succinct, but I think I would hate C++ at least 80% less if
method definitions were searchable using simple tools (or by
eye). Trying to find the right definition in a codebase that
defines hundreds of methods with the same name is awful
especially if inheritance is involved.
The reasons that Stroustrup gives for building on C have little to do with appreciation for C and everything to do with exploiting its success: he declares that C++ "has to be a weed like C" and enumerates C's advantages as being "flexible", "efficient", "available", and "portable". The last two of these simply reflect the growing popularity of C at the time. "Efficient" (as Stroustrup describes it) is implicit in K&R's description of a "low level" language, and "flexible" aligns with K&R's description of C's generality.
What we're left with then, is an intention to claim near-compatibility with C in order to supplant it as the general-purpose low-level language of choice. But he dislikes C, and those of its users not receptive to his ideas. Notably, Stroustrup does not consider being pleasant, expressive or not too big as advantages of C. That might go some way to explaining C++.
C has been at peace with itself for a long time. When the first edition of K&R was published back in 1978, its authors wrote reassuringly that C "wears well as one's experience with it grows."
In contrast, C++ seems to be at perpetual war with itself, because it hates its primogenitor. That much is obvious to me from the way that Stroustrup writes the asterisk on the lefthand side of a pointer declaration. He wants to dissociate his language from K&R's syntax, but he cannot, so he operates in a state of denial. Now he has an army of acolytes, not just copying him, but coming up with weird justifications such as "types are very important in C++" (but not in C?), or alleging that "C programmers think differently" (they don't).
In "The Design and Evolution of C++" (1994), Stroustrup wrote:
The C trick of having the declaration of a name mimic its use leads to declarations that are hard to read and write, and maximimises the opportunity to confuse declarations and expressions.
It's almost beside the point whether you agree with Stroustrup or K&R. The latter created a language that they enjoy, according to their own principles, whereas the former rails against the syntax of his own language, which he copied and cannot change. Which stance do you find more attractive?
It's hard to read Herb Sutter and not reach the conclusion that he hates C too, given the way he hand-waves away incompatibilities between fundamentals of C grammar (e.g. return type on the left, explicit types, multi-word type specifiers) and his preferred way of writing C++ (return type on the right, type inference, broken grammar for multi-word types). I've often wondered how high you could stack changes on C's grammar before it collapsed; I didn't realise until recently that had already happened.
Unfortunately, C programmers cannot ignore the existence of C++, any more than C++ programmers can ignore C. At one time, I would type "new" as an identifier almost every day (usually paired with "old"), go back and delete what I had typed, then try to think of a stupid synonym like "fresh" or "replacement".
The other reason I cannot ignore C++ is that I work professionally on a mixed codebase, and C++ has failed to live up to its claim of compatibility with C. Some of the most powerful and enjoyable features of C99 (namely compound literals and designated initializers) are not supported by C++, although C++20 finally adopted designated initializers in an incomplete form that is subtly incompatible with C. Worse, it's impossible for designated initializers in array declarations to ever be properly supported in C++ because C++11 standardized a conflicting syntax for lambdas.
After I went on a C++ training course with some colleagues,
the main effect was not that we began writing C++, but that
we began to use const more in pointer
declarations. C++ has a separate concept of "references",
which are similar to pointers, but with three key
differences:
The first of these properties can easily be implemented in C,
using the const qualifier:
int *const x = &y; // x can only point to y
The second (non-null) property cannot be enforced by C's type system. The logical way to add nullability information to C without breaking its syntax or semantics would be a new pointer target type qualifier:
_Optional int *z = malloc(10); // z can be null
You might be wondering why I have written
_Optional instead of nonnull or similar.
That's a long story for another
day!
In expressions, the unary operator & gets
the address of an object; it's the opposite of the
dereferencing operator, *, which gets an object
from its address. If & were allowed in C
declarations then you might reasonably expect it to cancel
out * in the same way.
In C++ declarations, & instead declares a
reference and has the opposite meaning in comparison to its
use in expressions. This is nonsensical:
int a, // 'a' has type 'int'
*b, // dereferencing pointer 'b' yields 'int'
c[3], // elements of array 'c' have type 'int'
d(float), // value returned by function 'd' has type 'int'
*e(float), // dereferencing return value of 'e' yields 'int'
&f = a, // address of 'f' has type 'int' ?!
*&g = b; // 'g' has type 'int' ?!
The only reason that * appears as part of
pointer declarations is to allow the declaration syntax to
mimic the syntax of expressions. Yet, when a C++ reference
(declared using &) appears in an expression,
& is not required!
C and C++ have grown up together as rivals, each borrowing from the other. As competition usually does, this has improved both languages. Here are some features of C++ that I'm happy to see in C:
for statements.
int in declarations.
Thanks, C++! You made C better.