Having identified the need for a fast 3-D graphics API that can be transparently implemented in either hardware or software, I proposed a shared-library solution based on Silicon Graphics's popular OpenGL graphics standard. This was to be implemented as a relocatable module, which is the standard mode of implementing language-independent shared code libraries under RISC OS.
In this chapter I shall explore further some of the implementation issues for such a module, and outline how these investigations informed my design decisions.
A single RISC OS module may implement only one SWI 'chunk' (allocated range of SWI numbers), and there is a limit of 64 SWI numbers per chunk. In contrast, OpenGL commands number more than 170.
The first step in adapting OpenGL for my purposes is therefore to find methods of reducing the number of commands in the API to a reasonable level.
A "MiniGL" is a partial implementation of the OpenGL graphics standard. These reduced implementations came about for two reasons: The number of OpenGL commands actually used by games programmers is relatively small, and 3D cards do not generally support acceleration of all features in hardware.
Full implementation of OpenGL drivers for a graphics card must include software emulation of all unaccelerated features. This software takes much longer to develop than a MiniGL driver, since compliance to ARB10 standards must be 100%. Therefore full OpenGL implementations are not always shipped with consumer-level 3-D graphics cards. [20]
Although originally designed only to allow hardware acceleration of iD software's game Quake, MiniGL was quickly adopted by other developers as a psuedo-standard for OpenGL games software.
Since the main application area at which my graphics library is targetted is that of computer games, there is a strong argument that all that is actually required is a MiniGL rather than a full OpenGL implementation. Which OpenGL functions should be included, though?
Due to time constraints, I was not able to do large-scale research into the frequency of use of different OpenGL features in graphics software. However I compiled an extensive list, from various sources, of those OpenGL functions supported by different MiniGLs (see Appendix I).
There appear to be essentially two 'standard' MiniGL command sets: The original 3dfx Quake MiniGL driver (around 40 functions) and, more recently, the 3dfx Quake II MiniGL driver (around 75 functions). Other MiniGLs seem to support a slightly different set of functions, based around one or other of these basic subsets.
Other information gleaned about the Quake/QuakeII MiniGLs:
This research should provide some guidance as to the minimum subset of OpenGL functionality that my GL module should implement in order to allow development and porting of 3-D games software.
The ANSI C declarations of many OpenGL commands consist of the same basic function name, with various suffices to describe the number and type of the parameters11:
|
Whereas the first version of the glVertex()
command takes 3 floating-point arguments, the second version
takes a pointer to an array of 2 sixteen-bit integers (the
z coordinate is implicitly set to zero). In all other
respects the two commands are identical.
It be would possible to retain this flexibility of accepting parameters in a variety of formats, yet still reduce the number of separate API entries, by to encoding the number and type of SWI parameters in an extra register. One scheme of encoding this information would be as follows 12:
| R0 bits | Meaning |
| 0 - 7 | Number of parameters {1 | 2 | 3 | 4} |
| 8 - 15 |
Code indicating type of parameters {b |
s | i | f |
d | ub | us |
ui }
|
| 1 = byte | |
| 2 = short | |
| 3 = int | |
| 4 = float | |
| 5 = double | |
| 6 = unsigned byte | |
| 7 = unsigned short | |
| 8 = unsigned int | |
| 16 - 23 |
If set then R1 points to an array of values of the
specified number and type v]
|
However, passing such a type-of-parameters code would carry its own cost in marshalling an extra function argument, and also in interpreting the encoded type information on entry to the SWI handler. Whilst avoiding myriad separate function definitions it would do little to decrease the actual complexity of the graphics library.
It is also worth noting at this point that the ARM processor
only naturally supports a limited range of numeric formats.
Whilst it is possible to access and manipulate data in other
formats, this is generally tricky and costly. Data may only
be loaded and stored in aligned 32 bit words
(LDR/STR) or individual bytes
(LDRB/STRB). Half-word (16 bit)
values must be loaded using a combination of
LDRB instructions and an ORR to recombine
the data in a single register13.
Signed values are represented in ARM registers as 2's complement 32-bit binary integers, with the sign in bit 31. Therefore byte or half-word values naively loaded into the bottom 16-bits are naturally unsigned. This can be rectified by logically shifting a 2's complement byte/half-word value left into the top bits (to make the sign bit significant), and then arithmetically shifting right to 'extend' the sign bit:
|
In practice, it is rare for native data to be stored in any
but the two natural formats of signed 32-bit integer and
unsigned 8-bit integer (corresponding to the GL types
ubyte and int respectively). Unless there
are large volumes of 16-bit data "...simply treating it as
32-bit data is likely to be the easiest and most efficient
technique" (ARM Ltd, 1994).
GL types that could not be naturally manipulated from ARM
assembly language are byte, short,
ushort and uint, but as it happens
the natural ubyte and int types are
perfectly appropriate for representing the two main types of
graphics data - RGB colour components (0-255) and cartesian
coordinates (±2147483647).
For example, versions of the glColor() command
are defined to accept data in every conceivable format.
However, specifying colours using (say) three double
precision floating-point values would be pretty silly given
that this would likely require the FP emulator to be invoked,
and in any case the underlying video hardware only supports
24-bit colour.
The standard RISC OS format for RGB colours is for three
unsigned bytes representing red, green and blue values to be
packed into a single 32-bit word as
&BBGGRR0014. The ColourTrans module
takes parameters in this format, and it has the advantage
that if rotated right by 8 bits the data can be written
directly to the framebuffer (in 24bpp screen modes). The
version of glColor() most closely resembling
this native form is
|
and there seems little point in accepting data in any of the
other formats, given the necessary extra API entries and cost
of format conversions. The likelihood of RGB component
resolutions higher than ![]() (giving 16.7 million
colours) ever being required seems negligible.
(giving 16.7 million
colours) ever being required seems negligible.
In short, there is no real precedent for a RISC OS module to accept SWI arguments in a wide variety of formats. Furthermore, where the number of parameters is small enough, SWIs invariably pass these in registers rather than passing a pointer to a block of memory.
In my adaptation of OpenGL, I decided therefore that the onus should shift to the client program to provide parameters in a suitable format. This might make some client programs slightly larger, since arguments may have to be loaded into registers from memory, and/or converted from foreign formats. However, it makes the design of the graphics library much simpler and reduces the number of separate SWI definitions necessary without increasing the complexity of function entry.
Even if the format of the client's data does not coincide with the library's internal format, having the client marshal arguments in the correct format cannot be any more costly than if this had been done inside the library15. For instance, supposing a client program had a real need to use signed 16-bit vertex coordinates:
|
(...repeat as above for y (R1) and z (R2) coordinates)
|
The key difference here is that the conversion is not being done in the GL module at an extra 'uncertainty cost' of interpreting a type-of-parameters argument, nor by adding another entry point to the API. Also, the programmer can see quite clearly the extra cost imposed by the conversion.
Some OpenGL functions, such as Rect() or
DrawArrays(), are strictly-speaking redundant,
since the equivalent operation can be performed by a
combination of other commands. For example, the command
Rect2f(x1,
y1,
x2,
y2) is equivalent to
the following command sequence:
|
From the point of view of producing a reduced OpenGL implementation, such composite functions could therefore be omitted entirely or implemented transparently by support code. However, there are technical arguments in favour of including these 'redundant' functions, beyond the obvious advantage that client programs become more elegant and succinct.
All programming languages have function call overheads which may involve stack extension, allocation of workspace for local non-register variables and preservation of caller registers. Under RISC OS there is a considerable overhead when invoking module code via the ARM's SWI instruction, over and above that of a simple branch-with-link to a statically linked function:
Whilst the call overhead described is not prohibitively costly where SWIs are used relatively infrequently, it can be very significant factor in limiting the performance of code where a large number of SWI calls are made. This is especially true of invoking SWIs from C programs, where they are typically called through an APCS veneer (in order to preserve register variables and allow argument type-checking by the compiler) rather being than being compiled in-line.
Although a SWI interface to a graphics library is not rendered impractical by these considerations, it will be important during the design process to bear in mind the overheads of repeated function calls. Notwithstanding the need to scale down the OpenGL API, I decided to include those features of the specification that help to reduce this overhead.
Briefly, the relevant OpenGL features are vertex arrays and display lists. Vertex arrays allow automatic sequential access to object data, in an attempt to rectify the fact that "vertex specification commands... require many command executions to specify even simple geometry" [1]. Display lists allow groups of GL commands and their arguments to be stored for subsequent execution, and can be particularly effective where they allow the client program to avoid recomputing function arguments.
Clearly, both these features can reduce the number of individual function calls necessary for most programs.
There are existing graphics extension modules within RISC OS, such as FontManager (outline fonts), Draw (PostScript-type drawing) and SpriteExtend (JPEG support). These extend the basic character, vector graphics and sprite plotting facilities provided by the RISC OS kernel, co-operating seamlessly with the VDU drivers and hence with each other.
In the case of the Draw module, "All moving and drawing is relative to the VDU graphics origin...", "None of the Draw SWIs will plot outside the VDU graphics window..." and "All calls use the colour... set up for the VDU driver." [3]
The outline font manager is also closely integrated with the
VDU drivers, even trapping UKPLOTV (the vector
for unknown plot command codes) in order to allow font
plotting via the standard VDU command stream.
If my adaptation of OpenGL could be integrated this
closely with the existing VDU graphics system then I could
dispense with many of the more mundane GL commands, such as
those controlling the framebuffers and basic pixel area
manipulation operations (e.g. glDrawBuffer(),
glReadPixels(), glCopyPixels() and
glDrawPixels()).
For example, this OpenGL command sequence to change draw buffer and clear the background to white
|
is equivalent to the following RISC OS calls:
|
Whilst the OpenGL version is undoubtedly more readable, there seems little point in needlessly duplicating functionality that is already provided by the existing graphics system.
It is less clear whether, like the Draw module, it
will be possible to dispense with the glColor()
command and use the VDU drivers' current graphics colour
instead: In fact, the only reason that Draw is able to
do this with such apparent ease is that it uses the VDU
drivers' own horizontal line fill routine (the address of
which can be read using OS_ReadVduVariables).
The foreground and background graphics colours maintained by the VDU drivers each consist of a colour number, plot action (e.g. AND/EOR/overwrite) and optionally an Extended Colour Fill. ECFs use repeated pixel patterns to dither colours, giving the illusion of more colours than are actually present. The correspondence between colour numbers and colours depends upon the current screen mode and palette. [3]
In OpenGL, colours are processed internally in RGB format, and may be subject to lighting, fog, clipping and interpolation before finally appearing on the screen [1]. Given how far removed the use of a colour is from its specification, I do not feel that using the current GCOL in for this application is really appropriate16.
In any case, for window managed programs the old GCOL system is strongly deprecated in favour of the new true colour system provided by the ColourTrans module17. Given an RGB palette entry ColourTrans can set the current GCOL and ECF fill to automatically give the best possible approximation in any screen mode. (Shown in the example code above.)
Many OpenGL commands such as Enable() and
Disable() are highly generic, therefore one or
more parameters may consist of an enumerated value that
specifies more precisely the desired operation. There are a
large number of symbolic constants defined for this purpose
that are used to refer data types, state variables, bitmap
image formats, and any other non-numeric parameters. In C
language implementations, these constants are named in order
to increase readability:
|
Since any existing OpenGL programs will at the very least require re-compilation before being linked with my graphics library, I see no particular reason to adopt the standard C-language bindings of such symbolic constants. Indeed, there are good reasons for not doing so:
The OpenGL specification requires that if a command
"...is passed a symbolic constant that is not one of those
specified as allowable for that command, the error
INVALID_ENUM results." [1] If we are to implement
thorough checking of symbolic values passed to library
functions, these checks should be as fast as possible and
optimised for the non-failure case.
Because the ARM uses fixed-length 32-bit instructions there are a limited range of constant values that can be incorporated in an instruction. It must be possible to encode any immediate constant as an 8-bit value rotated right by 2n bits, where n is a 4-bit constant (e.g. the value 1020 would be encoded as '255 rotated right by 30'). [4]
Given this constraint, the values used for symbolic constants become significant. Unless they are valid ARM constants, then each time they are required (by client or library) they must be loaded from memory in a costly extra instruction. The following code snippet illustrates the overhead on entry to an imaginary function:
|
It would also be advantageous for symbolic constants for a
given function to neighbour each other. When checking the
validity of an enumerated value this would allow contraction
of a potentially long list of comparisons to a simple check
that ![]() .
.
Error handling conventions for SWI calls are very different from those of OpenGL functions, with SWIs actively raising errors unless suppressed and OpenGL taking a more passive stance:
When a SWI returns an error, the ARM's V (overflow) status bit is set and R0 points to a standard SWI error block. This error block consists of a unique 32-bit error number in the first word, followed by a textual error message. A program can prevent the current error handler from being invoked by setting bit 17 of the SWI number (the name is then preceded by an 'X'), and manually checking the state of the V flag upon return. [3]
This example shows suppression and detection of errors from a SWI:
|
With OpenGL, no error indication is returned by
functions. Instead, when an error condition is detected, a
flag is set and an error code is recorded. Subsequent errors
do not overwrite this recorded code, which persists until it
is cleared by the client program. Calling
glGetError() returns the code of the first error to
occur since the last call to glGetError(), and
clears the flag. [1]
Unless an application calls glGetError()
periodically (it is unlikely to do so after each GL function)
then execution of the client program will continue
uninterrupted, with any errors unreported.
I decided in the end not to implement
glGetError() in my graphics library, not because it
would be particularly difficult or expensive, but simply
because it does not seem necessary.
If I assume that high-level languages will be calling the
module SWIs through a type-safe APCS veneer rather than
in-line, then it would be a simple matter for the veneer code
to record errors returned by the SWIs and provide an
implementation of the glGetError() function. In
fact, even if SWIs are simply called via the standard C
library's _kernel_swi() function, then
_kernel_last_oserror() provides an implementation that
is near enough to Silicon Graphics's method, if not precisely
equivalent.
The chosen hardware and software environment raises a number of important considerations regarding numerical representation and computational accuracy.
The OpenGL specification requires that individual results of floating-point operations are accurate to about 1 part in 105, and that the maximum representable value for a floating-point number used to represent positional and normal coordinates be at least 232. For colours or texture coordinates, the maximum representable value must be at least 210. [1]
Whilst most single-precision floating-point formats meet these requirements, it is certain that an implementation of my graphics library using fixed-point arithmetic (as I had proposed) would not. However, my investigations of different numerical representations uncovered a number of issues surrounding floating-point arithmetic on RISC OS, which I shall outline.
As discussed in section 5 of the previous chapter, relatively few RISC OS computers have a hardware floating-point system, with the vast majority relying instead on software emulation of floating-point instructions.
Programmers writing speed-critical code for any platform try to avoid floating-point arithmetic where possible, because the extra computational complexity results in slower execution. Where floating-point instructions are emulated in software the potential performance gain of abstaining from floating-point arithmetic is even greater: ARM Ltd report that there are typically 10-100 operations involved when a floating-point instruction is decomposed into integer operations [8].
There are also technical reasons why using the floating-point
instruction set for my GL module would be problematic. The
Acorn Assembler manual states flatly that "Floating point
instructions should not be used from SVC mode." The reason
for this restriction is that the floating-point emulator is
only designed to be invoked from USR mode, therefore it
corrupts R14_SVC amongst other
complications.18
Robin Watts warns that "...calling FP instructions from SVC mode is a dodgy business. There are all sorts of issues to do with the way that the FP emulation is done. There are ways around the problem, but none of them are very nice, and all have some sort of side effect." [24]
Of course on a machine with a floating-point co-processor the emulator would not be invoked (except for some complex trigonometric instructions not directly supported by the hardware), and therefore none of the SVC-mode caveats would apply. However, using floating-point arithmetic in this way would severely limit the number of target machines for my GL module.
Real numbers with a fractional element can alternatively be represented by a pair of integers, known as the mantissa and exponent. The exponent is the position (in binary digits) of the decimal point in the mantissa. Mathematically, this relationship can be expressed as follows:
![]()
Where the exponent is a variable quantity unknown at compile
time, ![]() is a floating-point number, and must
be stored in a pair of integer registers or a special
floating-point register (in a co-processor).
is a floating-point number, and must
be stored in a pair of integer registers or a special
floating-point register (in a co-processor).
If the exponent is predetermined at compile time then ![]() is a fixed-point number which may be stored in a
single integer register. In layman's terms, the programmer
'pretends' that his values are larger than they actually are,
in order to preserve fractional accuracy in integer
arithmetic: 14.375 might masquerade as 232 exponent 4
(1110.1000), rather than being truncated to 14 (1110).
is a fixed-point number which may be stored in a
single integer register. In layman's terms, the programmer
'pretends' that his values are larger than they actually are,
in order to preserve fractional accuracy in integer
arithmetic: 14.375 might masquerade as 232 exponent 4
(1110.1000), rather than being truncated to 14 (1110).
Basic principles of fixed-point arithmetic:
RISC OS programmers have long made extensive use of fixed-point arithmetic. Fortunately the ARM's barrel shifter makes it very efficient at this, with the shift on the second operand of most ALU instructions giving one free exponent conversion per instruction. [7]
The main problem with fixed-point arithmetic is that the exponents used must be chosen very carefully for a particular application domain. As ARM's application note warns "Every shift left, add/subtract or multiply can produce an overflow and lead to a nonsensical answer if the exponents are not carefully chosen." [7]
If my library does employ fixed-point arithmetic, then one of the major tasks will be choosing suitable exponents and a defined range of valid input values, based upon the required fractional accuracy. This is more important when defining the functional interface of the library than elsewhere, since the internal implementation may subsequently be altered without upsetting client programs.
Unless the format of values passed to my graphics library corresponds to the internal format, a potentially costly conversion must be made for each value passed to the library. In choosing an API, therefore, I investigated the computational costs of format conversions.
In order to convert a number from floating-point to fixed-point format, you multiply by 2q, where q is the fixed exponent. In ARM assembly language this operation would be coded as follows19:
|
Conversely, to convert a number from fixed-point to floating-point format, you divide by 2q:
|
Unfortunately (unlike changing the exponent of a fixed-point value) it is impossible to use the ARM's fast barrel shifter to do these divide/multiply operations: Since the objective is to preserve fractional accuracy, the value to be converted must be in a floating-point register when the exponent conversion takes place.
The conversion to floating-point format is particularly
costly, since divide instructions "...are significantly
slower than multiplications and additions on most
floating-point systems." [8] One possible optimisation would
be to replace this division with a multiplication by the
reciprocal of the divisor (![]() ), since q is known at compile-time.
), since q is known at compile-time.
In the real world there is a high likelihood that the floating-point emulator would need to be invoked when passing floating-point arguments in co-processor registers. The speed penalty associated with this would probably outweigh the theoretical finding that it would be more optimal (multiplication vs. division) to force fixed-point implementations to take floating-point arguments rather than vice-versa.
Because most ARM systems do not have floating point hardware and emulation is prohibitively slow for fast real-time graphics applications, I decided that my graphics API should allow arguments only in integer registers, and that my initial implementation of the module will use only fixed-point arithmetic internally.
In making this decision I am following in a long games-programming tradition of sacrificing ultimate accuracy for speed. However, since my module is likely to be used for games and graphics demo programming rather than professional or scientific graphics applications, this should not present a problem.
Note however that this decision does not necessarily prevent certain implementations from using floating-point arithmetic internally, for greater accuracy where suitable hardware is available. After all, the fact that different implementations may be tailored to available hardware was one of the original goals of my system.
The next decision regarding the API was to choose the
exponent for coordinates expressed in fixed-point arithmetic.
I toyed with formats such as the 8-bits of fractional
information (accurate to ![]() ) suggested by ARM Ltd in their graphics
processing example [7], or the 16 bits of fractional
information (accurate to
) suggested by ARM Ltd in their graphics
processing example [7], or the 16 bits of fractional
information (accurate to ![]() ) used by Acorn's Draw module for
transformation matrices [3].
) used by Acorn's Draw module for
transformation matrices [3].
I eventually decided that the choice of exponent for user coordinates should be left entirely to the creator of each client program, who is after all the only person who knows the likely range of values for that particular application area.
Essentially this means that coordinates should be expressed in the most fine-grained units necessary to avoid fractions: For instance coordinates within a 1 metre³ world area might need to be expressed in centimetres in the range 0-100, rather than naively as fractional values between 0 and 1. Admittedly OpenGL programs ported from other platforms might need some (relatively straightforward) modification before they would work properly.
As in other areas, I was influenced in this decision by the design of Acorn's Draw module. This implements PostScript type drawing, where 2-D graphics are specified as a collection of moves, lines and curves. Since a general transformation matrix is used in drawing a path to the screen, the coordinates of the path are expressed in abstract user-defined units rather than screen coordinates. [3]
Similarly, in OpenGL positional coordinates are meaningful only in relation to each other - in abstract they have no direct correspondence to screen coordinates. They are given scale only having passed through the model-view matrix and the projection matrix. Ultimately, the final dimensions of a given primitive on screen are also dependent on the size of the viewport.
Naturally all positional and normal coordinates must
be expressed to the GL in equivalent units, including (less
obviously) those passed to calls that generate a projection
matrix from the coordinates of a specified view volume
(Frustum(), Ortho()).
The numeric format to be used for expressing transformation
matrices also needs to be decided. In general this is an
internal implementation issue, since virtually all
transformation matrices are set up with calls to
user-friendly functions such as Rotate() and
Scale(), rather than directly using
glLoadMatrix() or glMultMatrix(). (A
cursory search of many OpenGL example programs reveals
only a couple of instances of direct specification of a
matrix).
Provisionally, it seems that an exponent of 16 offers a good
compromise between fractional accuracy (![]() ) and maximum integer magnitude (±32767). However, I will have to
ensure that there is absolutely no doubt about the
suitability of this format before it is set in stone in the
API documentation.
) and maximum integer magnitude (±32767). However, I will have to
ensure that there is absolutely no doubt about the
suitability of this format before it is set in stone in the
API documentation.
The Draw module uses a novel dual format for its transformation matrices - the multiplier components are given with an exponent of 16 "...to allow accurate specification of the fractional part", but the translation components are given with exponent 8 "...so that the integer part can be large enough to adequately specify displacements on the screen." [3]
The resulting format of Draw transformation matrices can be illustrated thus, where Mx is a multiplier for x and Tx is a translation of x:
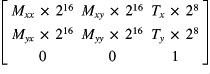
Further investigation is needed to determine whether differing exponents for the translation and scaling elements of transformation matrices would be also appropriate for my graphics library.
Within the client-server model of the OpenGL specification, there is a concept of multiple rendering contexts. This allows an implementation to simultaneously handle two client programs rendering in different windows. "A server may maintain a number of GL contexts, each of which is an encapsulation of current GL state. A client may choose to connect to any one of these contexts." [1]. However, the OpenGL specification does not define commands to initialise GL contexts or connect to them - this is left to a support library for the underlying operating system.
One way to implement this would be for my module to implement a SWI that initialised a new rendering context and returned a 'handle' for it (probably the address of the new context's state). The client would retain this context handle and pass it as the first parameter to every SWI that was called subsequently, analogous to the way a file handle is used for all operations on that file.
If a context handle were to be passed with every SWI then it would be good programming practice to check that this was valid, particularly if it were to be used directly as the address of the context's state. The simplest way to implement this would be to place an identifiable tag at the start of each context's state. Assuming the context handle is passed in R0:
|
This check imposes an extra penalty on function entry, but it would be the only safe way for a shared library to implement multiple contexts in a multi-threaded or pre-emptive environment. A support library would conceal this from client applications, who would each believe that they had the 'current' context.
An alternative method of implementing multiple contexts is provided by RISC OS itself: Modules may be multiply-instantiated, meaning that whilst there is only a single copy of the module code in memory, there may be multiple copies of the module's workspace. The workspace is a separate dynamically allocated area for storage of variables - constant data is stored within the main body of the module.20
Each copy of the module's workspace, together with the code, is referred to as an instantiation. "Changing which copy of the workspace is used changes the context of the module and allows it to be used for several purposes concurrently." [3] The operating system provides commands to create new instantiations of a module, rename an instantiation, and set the currently active ('preferred') instantiation.
Because this concept of multiple-instantiation closely parallels the multiple 'contexts' of the OpenGL client-server model, it should provide a good method of implementing these:
On the downside, client programs must make a SWI call to change the preferred instantiation, rather than simply passing a different context handle the next time the GL module is invoked. This is a calculated trade-off, based upon the (not unreasonable) assumption that a change of rendering context will be a comparatively rare event.
Since RISC OS is a co-operative rather than pre-emptive
multi-tasking system, I need not worry about client programs
interfering with each other's instantiations of the GL
module21. Each
client program need call OS_Module 16 only once
after each Wimp_Poll, in order to set theirs as
the preferred instantiation. Until the client relinquishes
control, it can issue commands to the GL module without
worrying about the preferred instantiation being changed.
Time constraints dictate that I need to simplify my project. I have therefore decided to abandon my original goal of replacing the existing esoteric RISC OS graphics API with the standard OpenGL API.
Being designed for professional graphics workstations, the OpenGL standard is just too big and complex to be sensibly implemented as a single RISC OS module, and in any case many of the facilities exceed those necessary for inclusion in a ROM-based consumer operating system. Other functionality duplicates that provided by the existing graphics system.
Instead, my graphics module will be based on the role of existing extension modules within RISC OS. These co-operate with the VDU drivers to extend the basic plotting facilities provided by the kernel, thereby forming a distributed rather than monolithic graphics system. Each such extension is targetted at a specific application area, rather than attempting to cater for all conceivable user graphics requirements.
The kernel's sprite facilities and the outline font manager are more than adequate for handling the bitmap graphics requirements of most programs22, and the Draw module can be used for desktop applications where bezier curves and other vector graphics primitives are required. Therefore, my graphics module will be designed to address the needs of the particular application area of 3-D games and graphics demos.
To this end I shall select a certain subset of OpenGL commands to be implemented, based largely on my research into MiniGLs used by games developers for other platforms. Composite commands such as those for vertex arrays and display lists may or may not be included, depending on their relative commonality/implementation cost and given the known overheads in invoking individual SWIs.
For the reasons discussed, the values chosen for symbolic constants will not necessarily correspond to those used in C-language implementations of OpenGL such as Mesa or Silicon Graphics's sample implementation.
In general, my graphics module will accept SWI parameters in a single format appropriate to the data being passed, even where the OpenGL specification defines versions of that function that accept different numbers of parameters in different formats.
My initial implementation will employ fixed-point arithmetic internally, with the emphasis on speed rather than ultimate accuracy. This allows me to avoid the issues surrounding invoking the floating point emulator from module code, and gives an opportunity to investigate the StrongARM's long multiply instructions as an alternative method of implementing long fractional accuracy.
The concept of multiple GL 'contexts' for commands will be
implemented using RISC OS's native mechanisms for the
multiple-instantiation of modules.
10 The OpenGL Architectural Review Board - the body that oversees conformance to the standard and extensions to it.
11 Note that multiple declarations would not be a necessity in languages that allow passing of argument type information to functions, such as C++ or Ada.
12 This was considered during the preliminary design phases but the idea was subsequently dropped.
13 The ARM v4 architecture added half-word load/store instructions, but these are only available on StrongARM processors and in any case cannot be used on Risc PCs because the memory system does not support 16-bit accesses.
14 Colours in this format are known for historical reasons as 'palette entries', since at the time palettes were the only context in which 24-bit true colours appeared(!)
15 Unless the process of argument marshalling happened to adversely affect register allocation in the client program - but this is not a possibility that merits serious investigation.
16 It would be necessary to convert the GCOL for internal processing by reading RGB values from the current palette - clearly a waste of time, especially given the reasonable likelihood that it was set up by ColourTrans (at some considerable effort) from an RGB colour!
17 Programs multi-tasking under the window manager are required to be screen mode independent.
18 David Ruck (2002) amongst others, informs me that "Changes were made in RISC OS 4 to support FP in SVC mode which will make it easier to use in future." However, restricting my graphics library to OS 4 (released relatively recently) would be undesirable.
19 Unless ![]() , which is unlikely since values would only be accurate
to
, which is unlikely since values would only be accurate
to ![]() or
or ![]() , it is impossible to express 2q as a
valid constant in an ARM floating point instruction.
Therefore 2q is illustrated as being loaded from a
nearby literal pool.
, it is impossible to express 2q as a
valid constant in an ARM floating point instruction.
Therefore 2q is illustrated as being loaded from a
nearby literal pool.
20 Modules that violate this rule are strictly speaking 'broken'. Any attempt at multiple-instantiation will fail horribly, and inclusion of the module in ROM is also impossible.
21 Here, I assume that the module will only be invoked from user-mode programs. If used from interrupt routines then there would be potential problems with the current user-mode program unknowingly 'losing' its preferred instantiation.
22 In the past programs have bypassed the kernel's sprite plotting routines in order to gain extra speed (see chapter 2), but there is likely to be more stigma attached to doing this in future because of the negative effect of such custom plot routines on Viewfinder hardware.